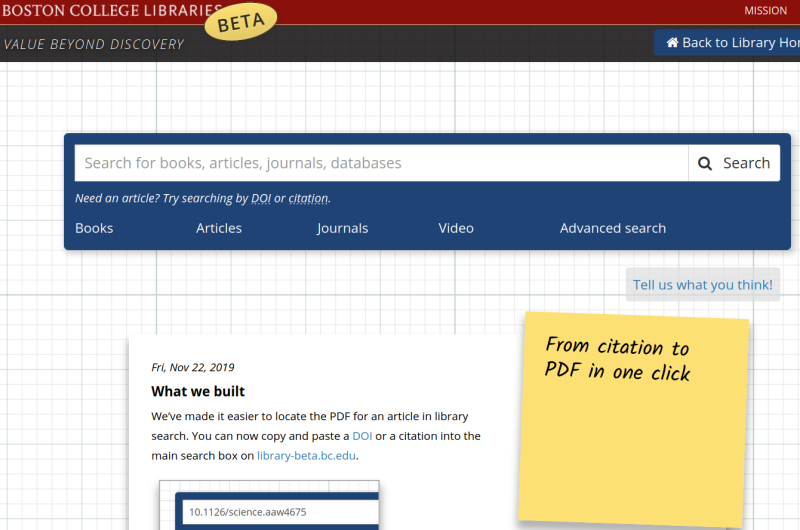
From Citation to PDF in One Click
- Leveraged user interview data to understand critical problem
- Led team through design and implementation
- Established pathway for similar projects in the future
Metadata, authentication, IP addresses, coverage, link resolvers, OpenURL: the system complexity involved in providing access to online library content does not map well to our users’ mental model. Users searching for known items have difficulty sifting through confusing results to recognize the correct match. If they manage to find the correct item, they are faced with a dizzying array of options in the link resolver.
Even when users choose the correct link, they still may encounter click through agreements, bad links, and confusing interfaces. Every click, every decision point, represents a barrier that users must overcome, and increases the likelihood that they’ll get frustrated and give up. Wasted time and failed attempts erode trust in the Library’s ability to provide access.
Our user interviews uncovered four major points of frustration for users. My goal for this project was to quickly iterate on a potential solution for Full Text Access while laying the groundwork for future projects focused on the remaining problems. I assembled a project team, including one developer, one reference librarian, and our electronic resources librarian. We sketched a five month timeline of weekly sprints. While this cadence and structure are common in the software development world, academic libraries routinely structure work as long term projects with all stakeholders in the room and wide scope. I wanted to demonstrate the advantages of a leaner approach to problem solving and pave the way for similar projects in the future.
Analyzing our user interview data made it clear that users frequently identify articles through conversations with peers, advisors, faculty, or other researchers in their field. Our search logs confirm that they often come to the library website with a specific known item to look for. We wanted to have a working solution live by the end of our 5 month project, so we kept the scope tightly focused on known-item searching.
Full text access is a well known problem in academic libraries, but most attempted solutions are still in their infancy. Our discovery platform, Ex Libris’ Primo, has not yet attempted to address the problem meaningfully, relying on the link resolver to provide access. EBSCO’s EDS platform performs well for the publishers’ own content, linking PDFs directly in search results when possible. Ex Libris’ Summon gets closest to providing consistently simple access through its use of direct linking, but only for about half of the total content. Both Summon and EDS provide access to the remaining content with the assistance of a link resolver.
InstantILL, a product of a small start up has some promising user experience elements. They present known item look ups as a formatted citation, giving users the ability to check and confirm accuracy before placing an InterLibrary Loan request. The developers have article access on their roadmap, but currently no working implementation.
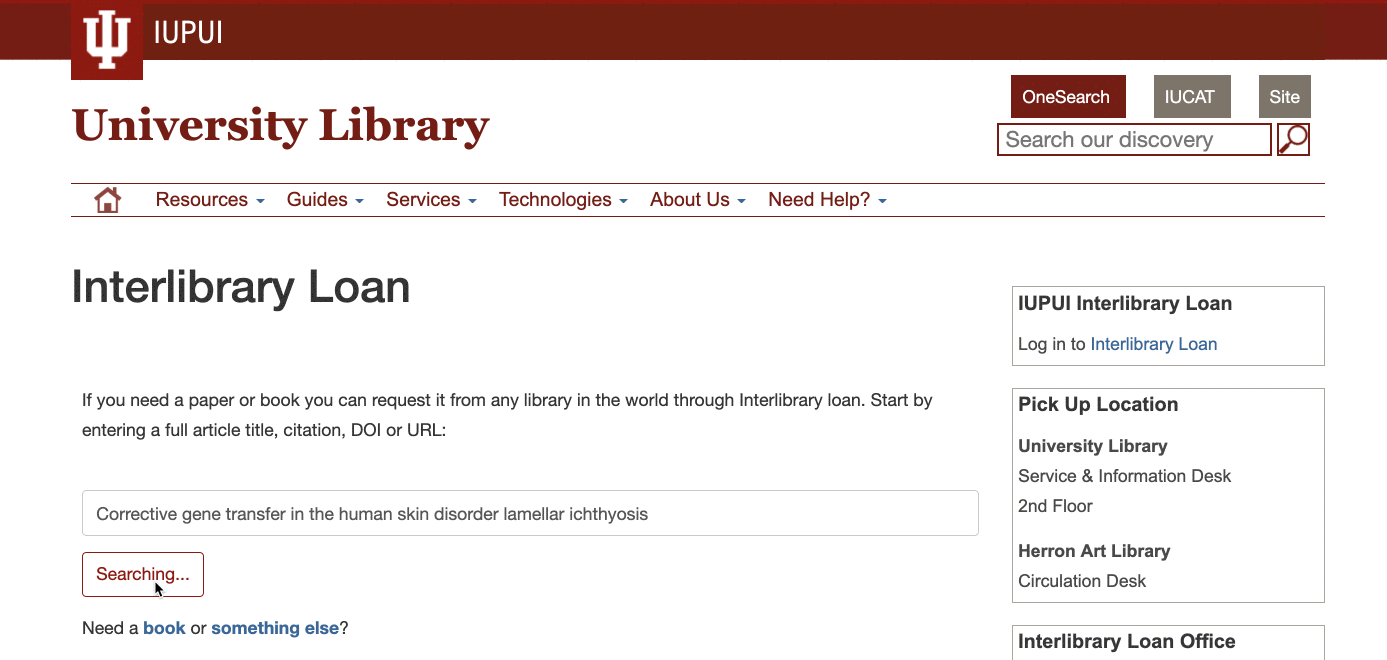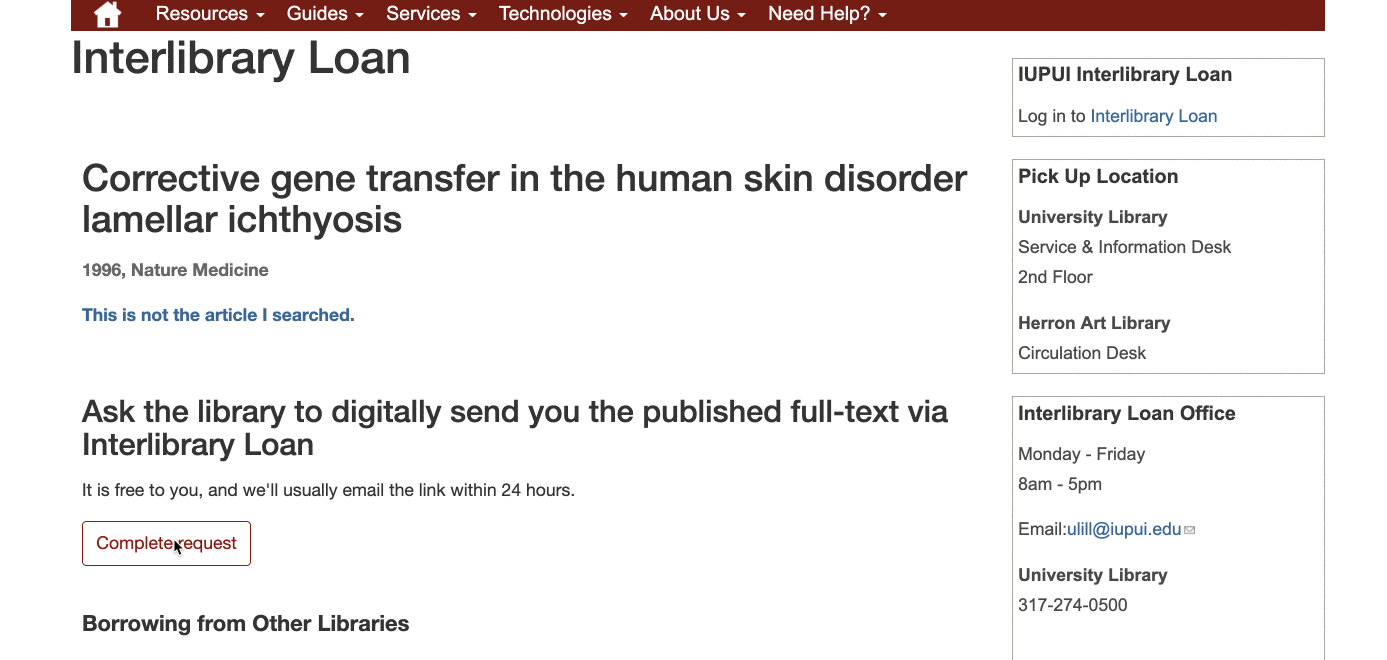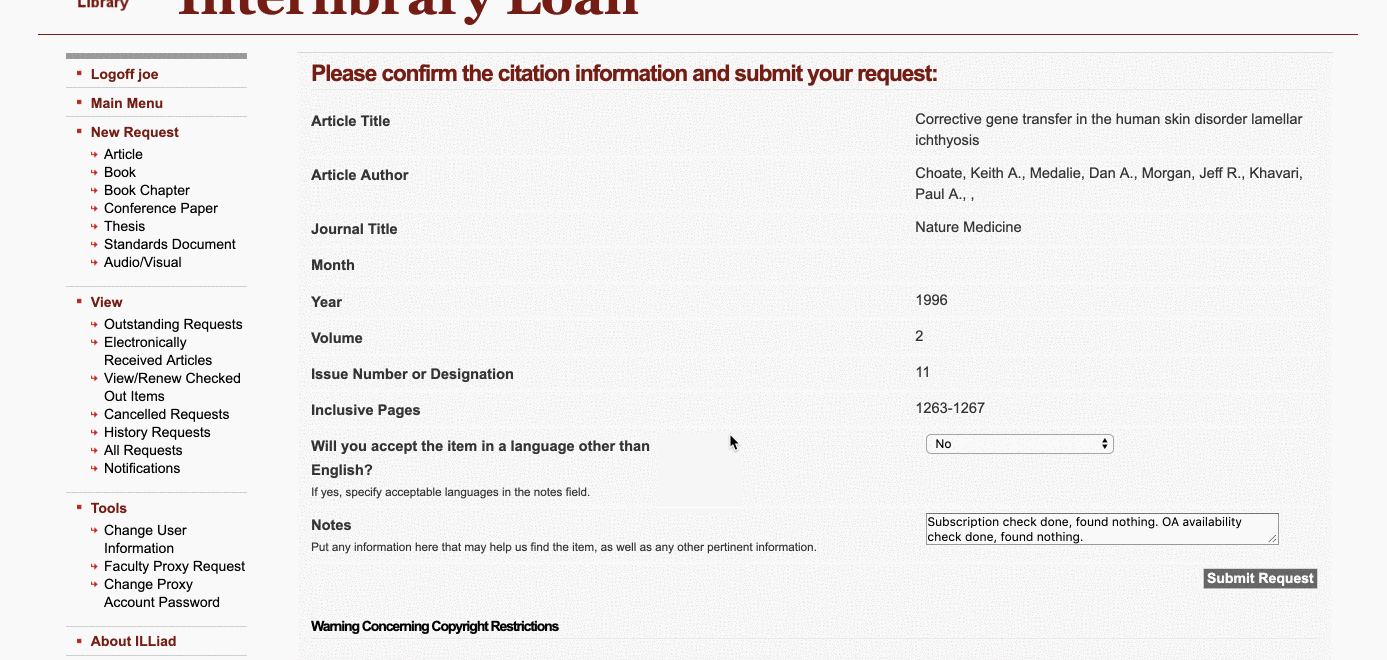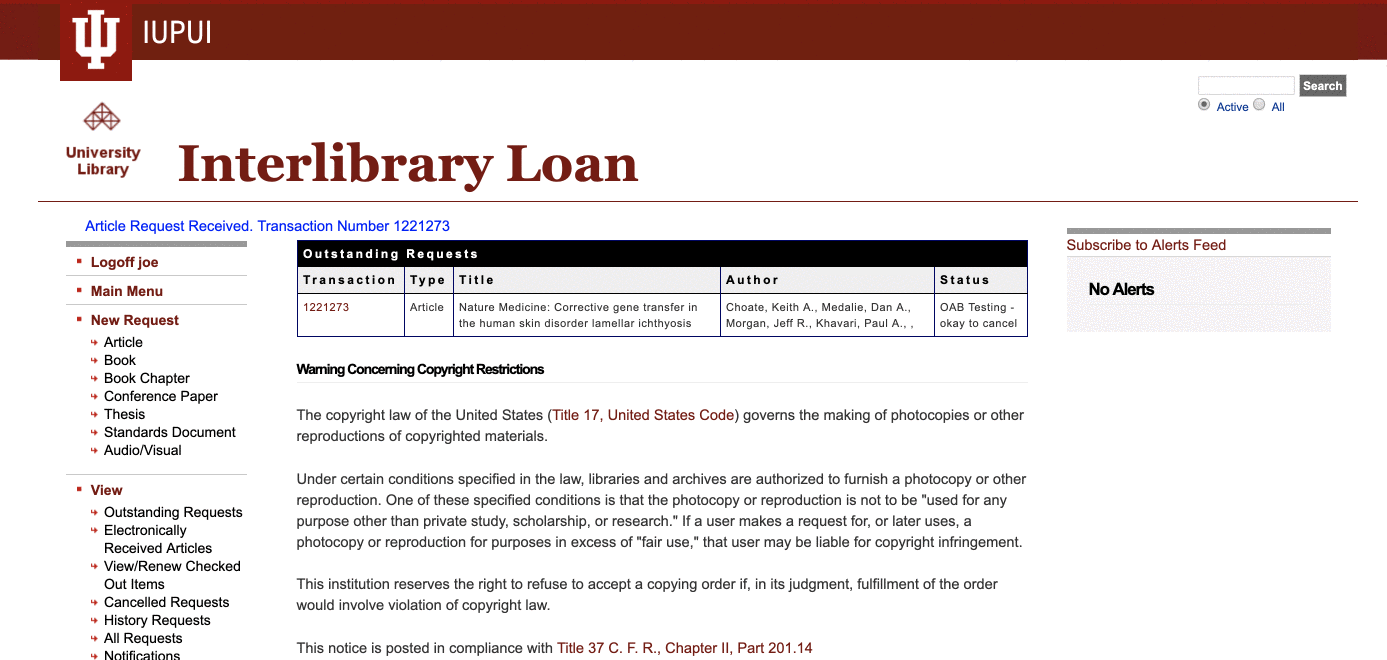
The most promising solution we encountered was Third Iron’s LibKey API. The product is a spin-off from their successful Journal browsing application, Browzine. With LibKey, they provide API access to obtain direct links to article PDFs. We were already using LibKey with Primo to add LibKey links directly in the search results. While this helps by providing more reliable links, it doesn’t address the problem of disambiguating results, and users are saddled with yet another button to choose from in an already cluttered interface.

Our project team had varying levels of design experience, but I knew that all of us would bring interesting ideas to the table. I led the group through a series of activities designed to explore ideas and solutions. We began exploring the problem with a mind mapping exercise, designed to help us make connections between the causes and effects of our problem. From there, I led the group through several sketching exercises. First, we used “crazy eights”, asking each person to sketch eight rough ideas on a single sheet of paper. Next each user chose their most salient idea and expanded on it with a 3-panel storyboard. As we shared our ideas and voted on them, we converged around the idea of integrating a known-item lookup feature directly into our search interface.
We then worked together to expand our storyboard and fill in more of the details. We sketched a design that reformatted a successful known item lookup as a citation, and provided a clearly labelled link to read the full text. We created a mock prototype by manually creating a few example items in our existing search interface.
I led us through the creation of a prototype test, and we ventured into the lobby to test with real users. We provided them with specific titles to search for and asked them to get to the full text. Several users responded with delight as they realized how easily they could get the item they were looking for. We noticed that some users had trouble realizing that they could simply enter a complete citation or DOI to look up the item. Once those users discovered the ability, everyone was able to successfully get to the full text in one click. I decided to add some contextual hints to the search interface to encourage the search behavior we were expecting.
Over the next two months, I led the team through the technical implementation. With a substantial amount of one developer’s time dedicated to the project, we were able to move quickly. Our implementation was up and running quickly, and we used the weekly sprints to address questions, iron out details, and address bugs along the way.
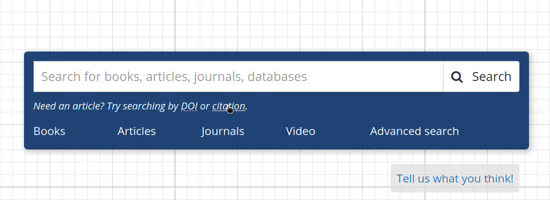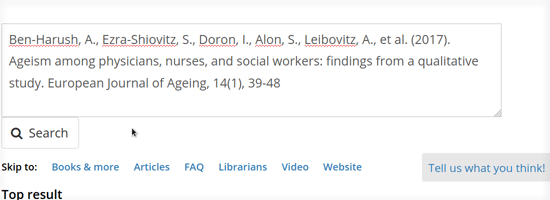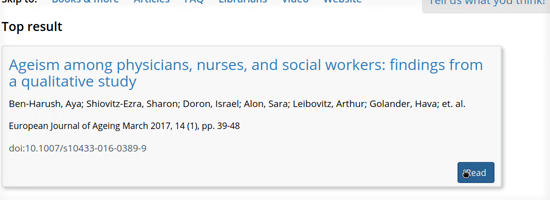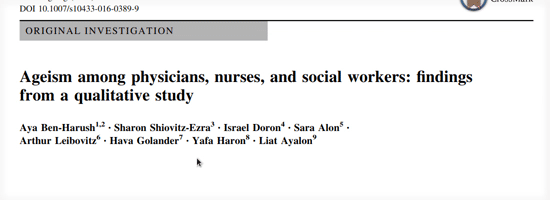
Full text lookup works by taking any search input and attempting to identify it as a known item lookup in addition to performing a typical search. First, if the search text includes a DOI, we immediately look it up in LibKey. Otherwise, if the search text is 20 or more characters long, we send it to the CrossRef search API. As a DOI registry, CrossRef contains the canonical metadata for over 100 million articles. Their search API is robust, and includes a relevance score. We constructed tests of the API from our search logs and used it to zero in on a threshold for finding the correct item. If we’re confident we’ve found the right item in CrossRef, we use the CrossRef metadata to display a formatted citation for the user. Then, we use the DOI to check LibKey for a direct link to the full text. Lastly, it’s all put together for the user, and the title and read button are linked to the full text.
Throughout the implementation we were able to reduce the likelihood of false positives to nearly zero. Still we wanted to roll out a test version of the feature before including it in our production site. Since the feature relied on integrating with our library website and search application, we needed a way to test it without confusing users. I designed a new beta site for the library with distinctive branding. The new site included the test version of our search application but stripped out everything from the rest of our website. In place of typical homepage content, I added a story introducing the new feature. We went live with the beta site in late November, but given the time of semester we understood traffic would be fairly low. This gave us the opportunity to test with a wider audience quietly. We called on public services staff across the library to test it out and introduce it to users they thought would benefit from it. This Spring, we’re promoting it more heavily and expect to roll the feature into production fairly quickly.